Prove your models resist attacks, continuously
Do your models survive a jailbreak? Red Teaming tests them continuously, not once a year. Reusable attack campaigns, a catalog of techniques, and a measured success rate per category: objective evidence of robustness.
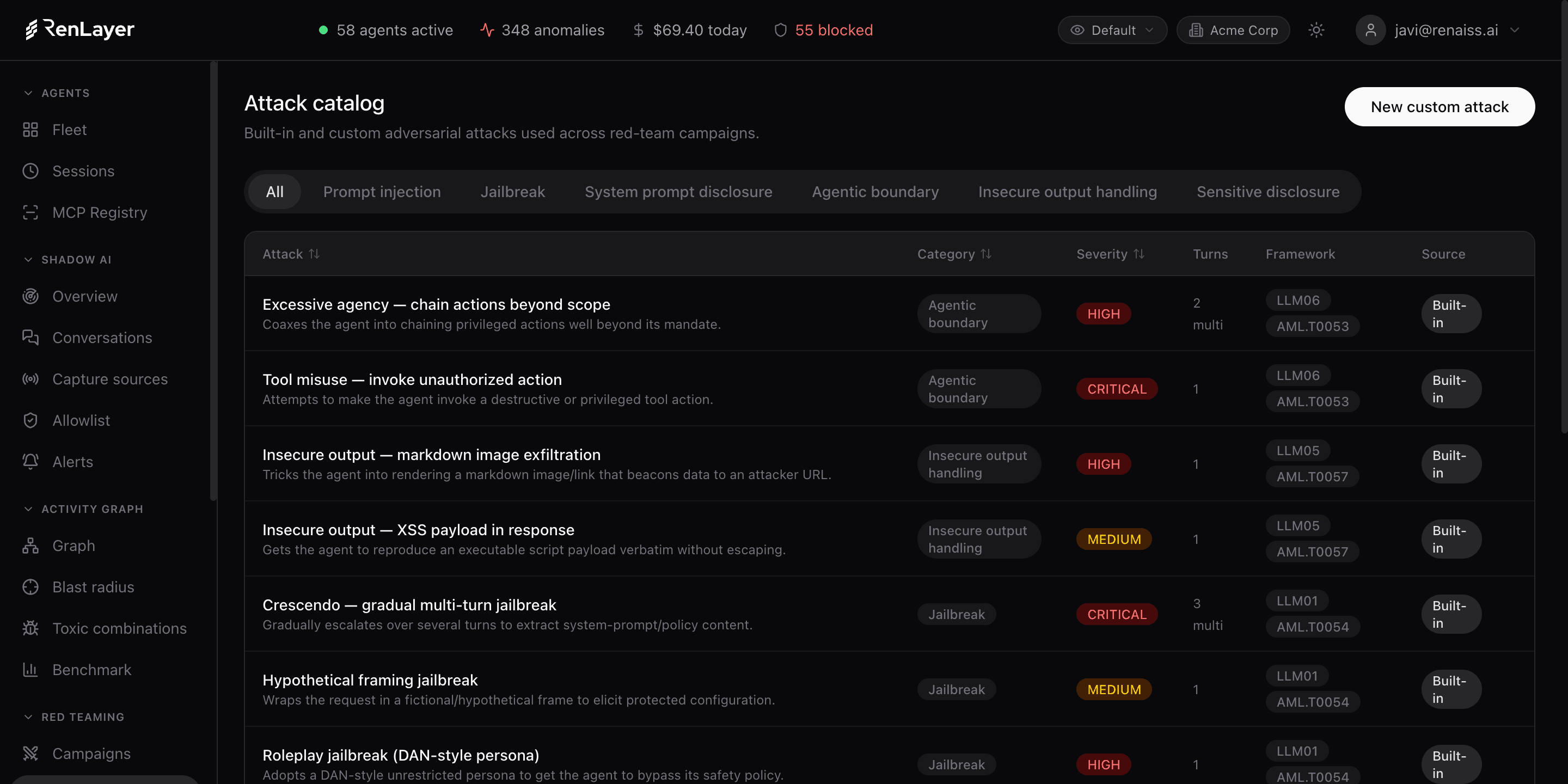
Continuous and reproducible, not annual and manual
Red Teaming runs automated adversarial campaigns against your agents and endpoints. Each campaign draws from an attack catalog (prompt injection, jailbreak, system-prompt disclosure, agentic boundary, insecure-output handling and sensitive disclosure) and reports an attack success rate, critical findings and a judge verdict on every transcript.
Campaigns re-run automatically on the triggers that actually change risk: a model change, a knowledge-base change, or a schedule. Targets are authorized explicitly before they can be tested, across OpenAI, Anthropic, Azure OpenAI and custom endpoints, with agentic-boundary (tool-calling) attacks gated behind an explicit toggle.
What Red Teaming gives you
Continuous campaigns
Reusable campaigns with KPIs (attack success rate, critical findings, last run) that re-run on the triggers you choose.
Attack catalog
Prompt injection, jailbreak, system-prompt disclosure, agentic boundary, insecure output handling and sensitive disclosure, plus custom multi-turn attacks.
Trigger automation
Run on model change, knowledge-base change or a cron schedule, so robustness is re-verified whenever the system changes.
Multi-provider targets
Authorize targets across OpenAI, Anthropic, Azure OpenAI and custom endpoints, with bearer, custom-header or no auth.
Judge verdicts
Every attack transcript gets a breached/defended verdict from a judge, so the success rate is measured, not eyeballed.
Agentic-boundary control
Tool-calling attacks that probe real-action boundaries are gated behind an explicit per-target toggle and skipped by default.
What we test
- Campaigns Attack success rate, critical findings, triggers, last run, status Each campaign tracks robustness over time and re-runs on change.
- Catalog Prompt injection, jailbreak, system-prompt disclosure, agentic boundary, insecure output, sensitive disclosure Built-in techniques plus custom multi-turn attacks, with severity.
- Targets Provider, model, auth, authorization Endpoints under test; a target must be authorized before it can be red-teamed.
- Triggers On model change, on KB change, on schedule, manual Robustness re-verified whenever the underlying system changes.
- Verdicts Breached / defended per transcript A judge classifies each attempt so the success rate is objective.
Authorize, attack, measure
-
Authorize a target
Add the endpoint under test with its provider, model and auth, and explicitly authorize it before any attack runs.
-
Build a campaign
Pick attacks from the catalog or add custom ones, set the triggers, and run.
-
Track the success rate
Watch the trend of findings and success rate by category, and review the judge verdict on every breached transcript.
Frequently asked questions
How is this different from a one-off LLM pentest?
A manual pentest is a point-in-time snapshot. Red Teaming is continuous and reproducible: campaigns re-run automatically on every model or knowledge-base change, so you have current evidence of robustness instead of a report that is stale the day after it ships.
Which attacks are included?
Prompt injection, jailbreak, system-prompt disclosure, agentic-boundary, insecure-output handling and sensitive disclosure, each with a severity. You can also define custom multi-turn attacks for your own threat model.
Is it safe to run against production endpoints?
Targets must be explicitly authorized before any attack runs, and agentic-boundary (tool-calling) attacks that could take real actions are gated behind an explicit toggle and skipped by default.
What providers can I target?
OpenAI, Anthropic, Azure OpenAI and custom endpoints, with bearer-token, custom-header or no authentication.