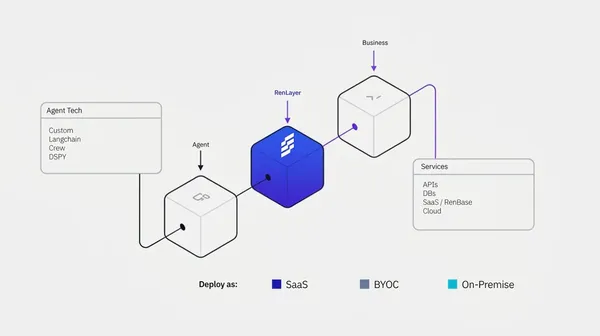
Making AI agents faster, safer, and leak-proof.
Our applied research team investigates how to optimize model performance by reducing latency and token usage, while protecting enterprise AI agents from attacks and data leaks.
Get a free assessment
Tokens are not just billing units. They are your performance budget.
If you are building AI agents, token usage directly impacts latency, cost, and response quality. Bloated contexts quickly become slower, more expensive, and less reliable. We research how to treat tokens as RAM and latency, not just cost.
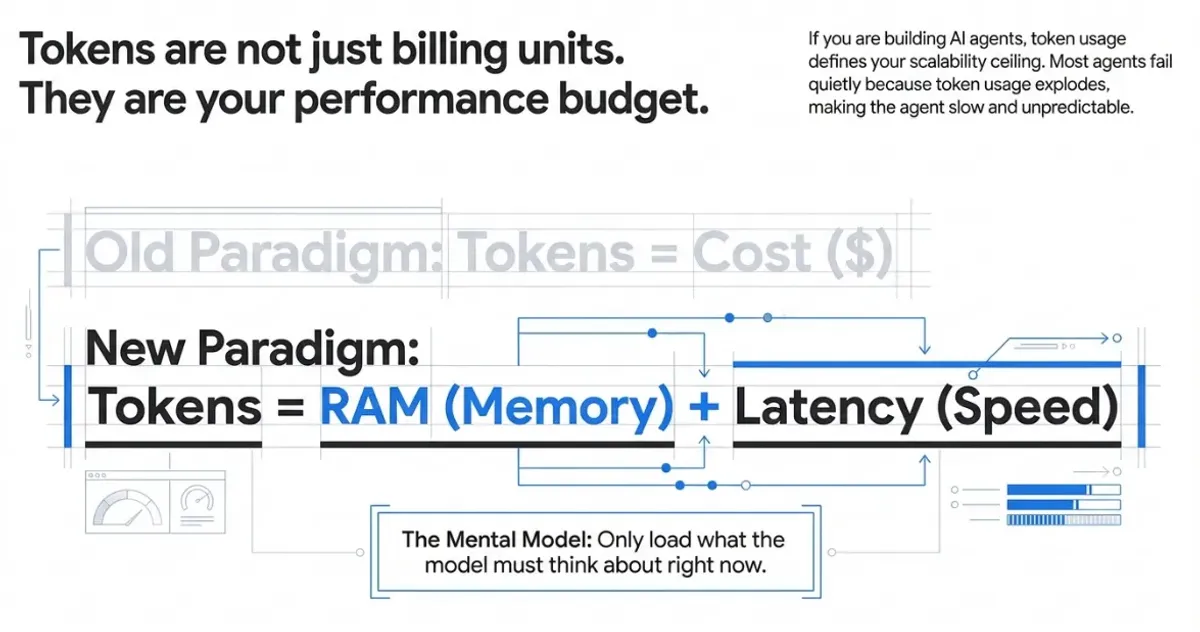
Optimize every token. Reduce latency. Multiply quality.
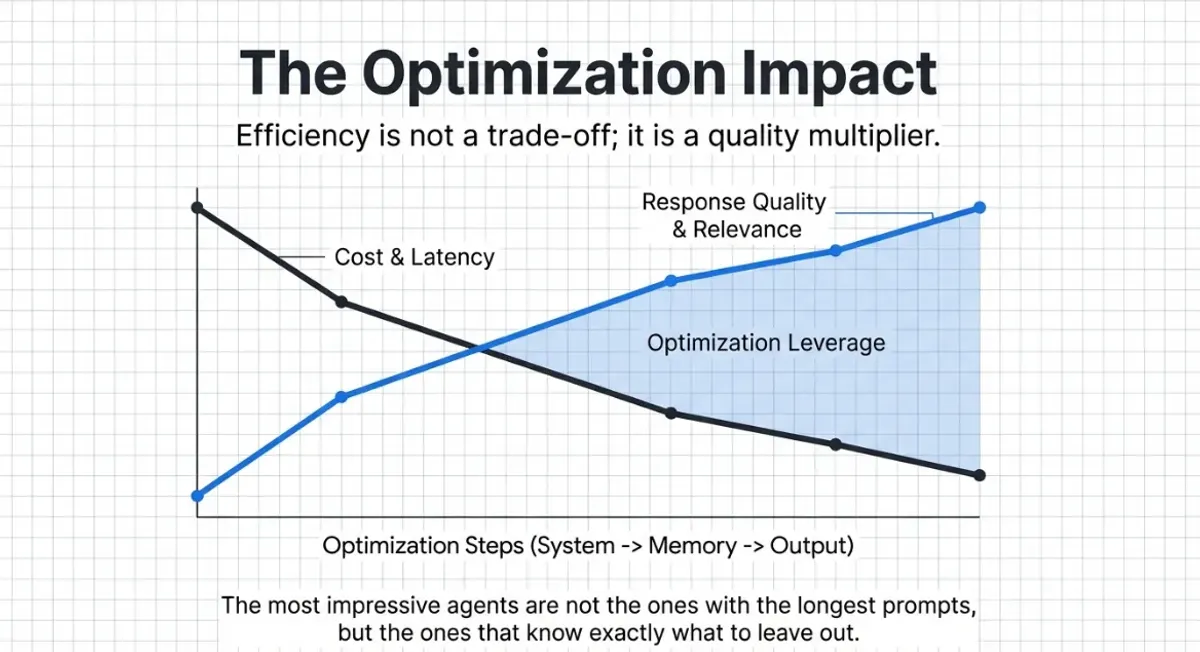
Our research into system instruction compression, request optimization, and prompt caching strategies helps enterprises get better results from every API call.

System Instruction Compression
Replace verbose natural language descriptions with structured rules and constraints to improve determinism and save bandwidth.
Request Compression
JSON minification, whitespace normalization, and empty field removal to reduce token count on every request.
Prompt Cache Optimization
Provider-side caching strategies, message ordering, and cache marker placement to maximize cache hit rates.
Defend your agents before attackers find the gaps.
Purpose-built threat detection for the unique risks that AI agents introduce to your infrastructure.
Prompt Injection Defense
Detecting and blocking injection attempts in real-time before they reach your models.
Data Exfiltration Prevention
Monitoring agent outputs for unauthorized data leakage patterns and blocking them.
Tool-Call Validation
Ensuring agents only invoke authorized tools with safe parameters within defined boundaries.
Stop PII leaks before they happen.
Real-time detection and redaction of personally identifiable information across all agent communications.
Real-Time PII Detection
Scanning agent inputs and outputs for sensitive data patterns including names, emails, IDs, and financial data.
Context-Aware Redaction
Intelligent masking that preserves agent functionality while removing sensitive information.
Compliance Mapping
Pre-mapped to GDPR and EU AI Act data handling requirements to simplify automated compliance workflows.
From research to production features.
Every optimization we discover becomes a feature you can toggle on. No code changes required.
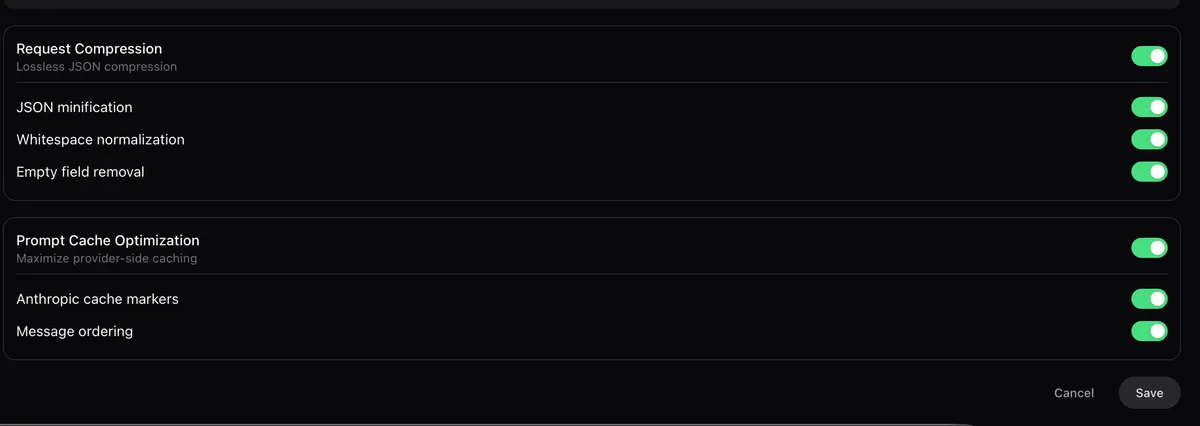
Request Compression
Lossless JSON compression saving tokens on every API call: JSON minification, whitespace normalization, and empty field removal.
Prompt Cache Optimization
Maximize provider-side caching for faster responses: Anthropic cache markers and optimized message ordering.
Shape the future of AI agent performance.
Join our research partner program and get early access to optimization features before anyone else.
Get a free assessment