Cut your AI token bill by 20 to 40%. Without touching a line of code.
RenLayer's transparent proxy compresses every request and maximizes prompt-cache hits, while budget caps and per-agent cost analytics stop runaway spend before it hits your invoice.
Get a free assessment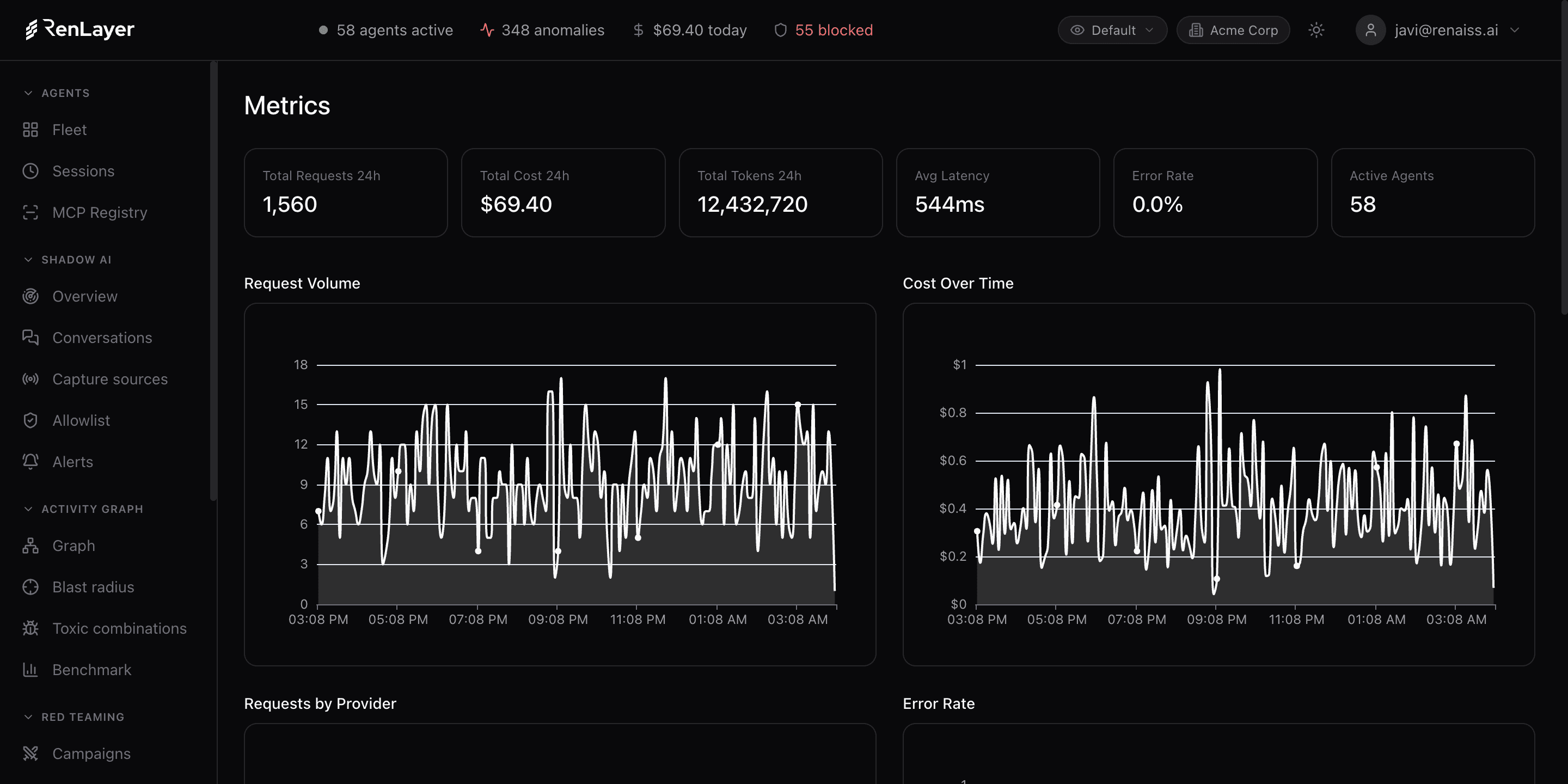
AI agents fail open on cost.
A single agent can quietly multiply your bill: bloated context windows resent on every turn, retry storms, un-truncated transcripts, silent model escalation, and tool loops with no cap. Most teams find out when the invoice arrives. RenLayer makes the spend visible and controllable from day one.
Read how AI agent costs run awayHow we cut the tokens
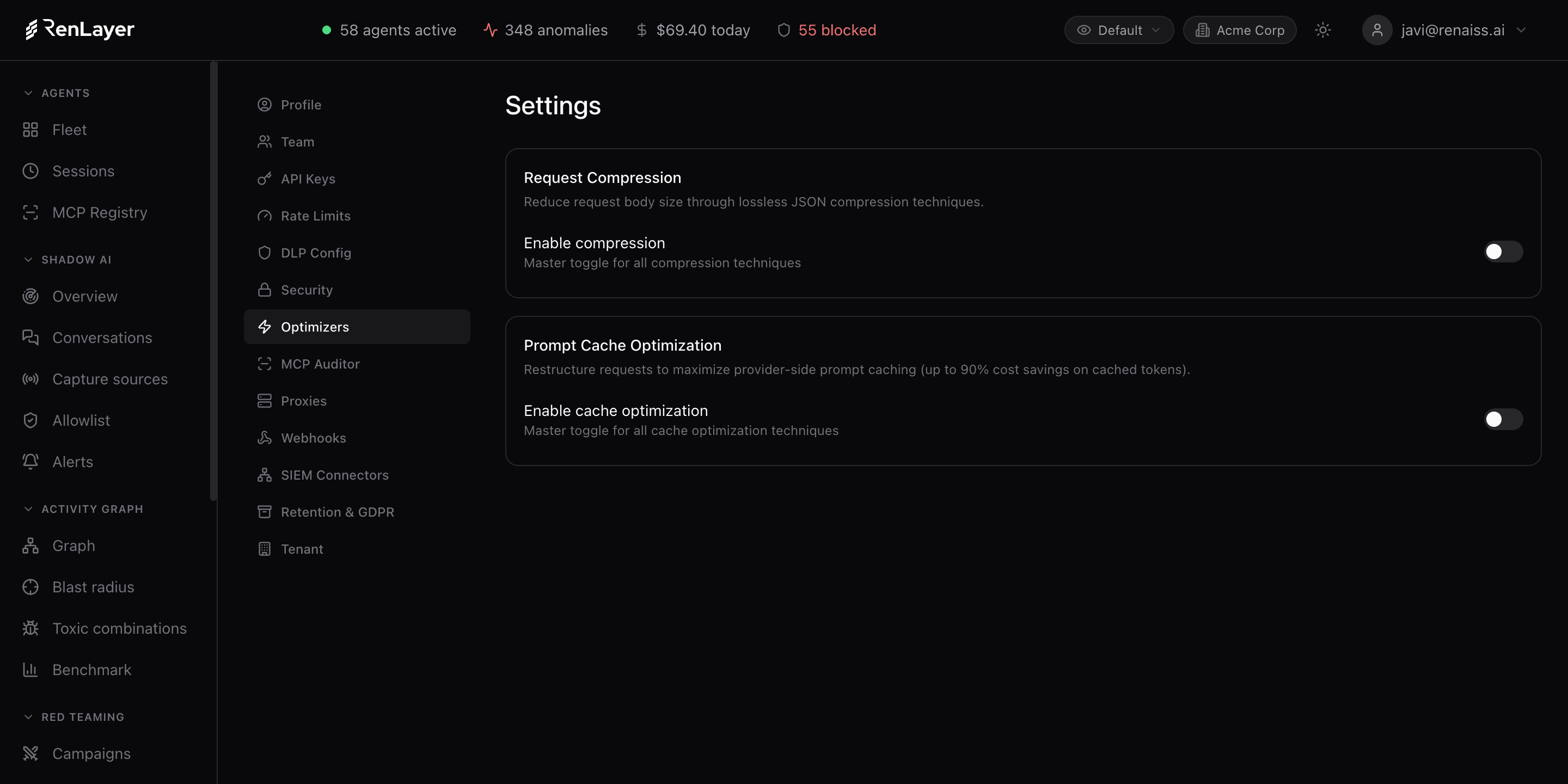
Three optimizers run inside the proxy and are toggled per agent. No SDK, no code change, and output quality is preserved.
Request Compression
Lossless JSON compression on every request: minification, whitespace normalization and empty-field removal cut tokens before the call leaves your network.
Prompt Cache Optimization
Requests are restructured to maximize provider-side caching with Anthropic cache markers and message ordering, for up to 90% savings on cached tokens and faster responses.
System Instruction Compression
Verbose natural-language instructions become structured rules and constraints, which improves determinism and trims the fixed cost of every prompt.
Optimization cuts the bill. Governance keeps it down.
The same proxy that compresses tokens also enforces the limits and surfaces the numbers your finance and platform teams need.
Budget caps and kill switch
Set per-agent and per-team caps on requests per minute or hour, tokens per minute and cost per hour. Halt a single agent or the whole fleet from one switch.
Cost policies
Block any single request whose estimated cost exceeds your threshold, or restrict expensive models, with the Cost Guardrail policy template. No code.
Cost analytics and attribution
Accurate token and cost data per agent, model, provider, user, team and department, with automatic alerts on cost spikes, even when the upstream UI hides it.
Live in production in under a day
1. Point your client at the proxy
Swap the base URL to the RenLayer endpoint and attach a few headers. No SDK, no rewrite, single-digit millisecond overhead.
2. Turn on optimizers and budgets
Enable request compression and prompt-cache optimization per agent, and set budget caps and cost policies from templates.
3. Watch the cost fall
Track cost per agent and model in Observe, catch spikes automatically, and attribute every dollar to the team that spent it.
Cost optimization FAQ
How much can I actually save?
Most teams cut 20 to 40% of tokens with request compression and prompt-cache optimization, and up to 90% on the portion of traffic that hits the provider cache. The exact number depends on your prompts, models and how repetitive your traffic is, which is what the free assessment measures against your own traffic.
Does compression change the model output?
No. Request compression is lossless: it removes whitespace, minifies JSON and strips empty fields without changing the semantics the model sees. Prompt-cache optimization reorders messages and adds cache markers; the content is unchanged.
Do I have to change my code?
No. RenLayer is a transparent proxy. You change the base URL and attach a few headers, then toggle the optimizers in the console. It works with any client and any provider, and you can disable it without breaking your agents.
How is cost attributed?
Every request is priced with accurate token and cost data and joined to the agent, model, provider, user, team and department, so you can run chargebacks and see exactly where spend comes from, even when the provider UI does not expose it.
Can I cap spend, not just measure it?
Yes. Set per-agent and per-team budget caps on requests, tokens and cost per hour, block over-budget requests with a cost policy, and use the kill switch to stop a runaway agent instantly.
Does the proxy add latency?
It adds single-digit millisecond overhead per request, and prompt-cache optimization often makes responses faster by increasing cache hits. Enrichment and logging happen after the response is streamed, so clients never wait on it.
See what you would save.
Start with a free assessment. We run a shadow-mode trial against your own traffic and show you the token reduction and the spend you can cap, in under a week.
Get a free assessment