Agentes de IA más rápidos, seguros y sin fugas de datos.
Nuestro equipo de investigación aplicada estudia cómo optimizar el rendimiento de los modelos reduciendo latencia y uso de tokens, mientras protege los agentes de IA empresariales de ataques y fugas de datos.
Evaluación gratuita
Los tokens no son solo unidades de facturación. Son tu presupuesto de rendimiento.
Si estás construyendo agentes de IA, el uso de tokens impacta directamente en la latencia, el coste y la calidad de las respuestas. Contextos inflados se vuelven más lentos, más caros y menos fiables. Investigamos cómo tratar los tokens como RAM y latencia, no solo como coste.
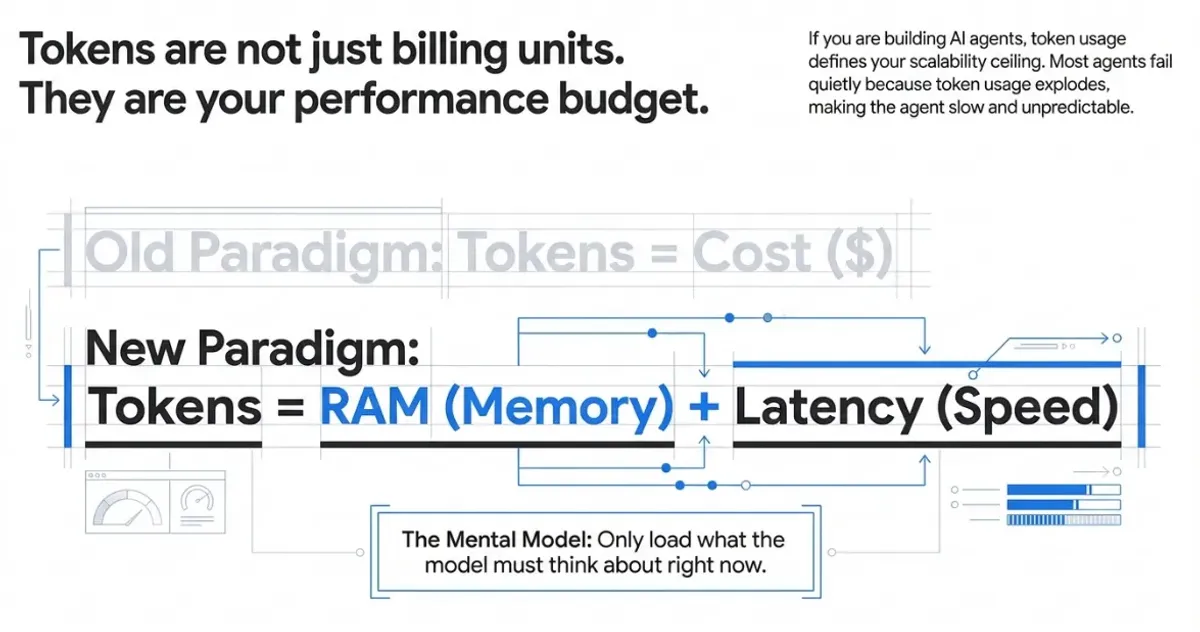
Optimiza cada token. Reduce la latencia. Multiplica la calidad.
Nuestra investigación en compresión de instrucciones de sistema, optimización de peticiones y estrategias de caché de prompts ayuda a las empresas a obtener mejores resultados de cada llamada API.

Compresión de Instrucciones de Sistema
Reemplaza descripciones verbosas en lenguaje natural con reglas y restricciones estructuradas para mejorar el determinismo y ahorrar ancho de banda.
Compresión de Peticiones
Minificación JSON, normalización de espacios en blanco y eliminación de campos vacíos para reducir el conteo de tokens en cada petición.
Optimización de Caché de Prompts
Estrategias de caché del lado del proveedor, ordenamiento de mensajes y colocación de marcadores de caché para maximizar las tasas de acierto.
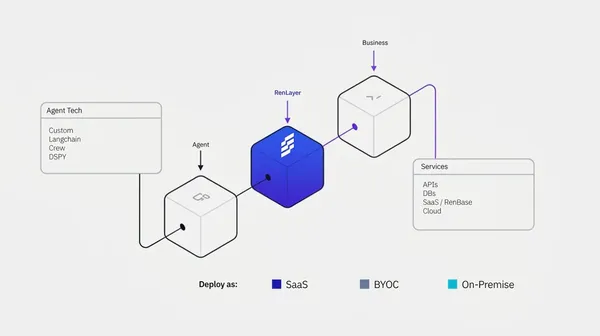
Defiende tus agentes antes de que los atacantes encuentren las brechas.
Detección de amenazas diseñada específicamente para los riesgos únicos que los agentes de IA introducen en tu infraestructura.
Defensa contra Inyección de Prompts
Detección y bloqueo de intentos de inyección en tiempo real antes de que lleguen a tus modelos.
Prevención de Exfiltración de Datos
Monitorización de las salidas de los agentes para detectar patrones de fuga de datos no autorizados y bloquearlos.
Validación de Llamadas a Herramientas
Garantiza que los agentes solo invoquen herramientas autorizadas con parámetros seguros dentro de los límites definidos.
Detén las fugas de PII antes de que ocurran.
Detección y redacción en tiempo real de información personal identificable en todas las comunicaciones de los agentes.
Detección de PII en Tiempo Real
Escaneo de entradas y salidas de agentes para detectar patrones de datos sensibles como nombres, emails, DNIs y datos financieros.
Redacción Contextual
Enmascaramiento inteligente que preserva la funcionalidad del agente mientras elimina información sensible.
Mapeo de Cumplimiento
Pre-mapeado a los requisitos de manejo de datos de GDPR y EU AI Act para simplificar los flujos de cumplimiento automatizado.
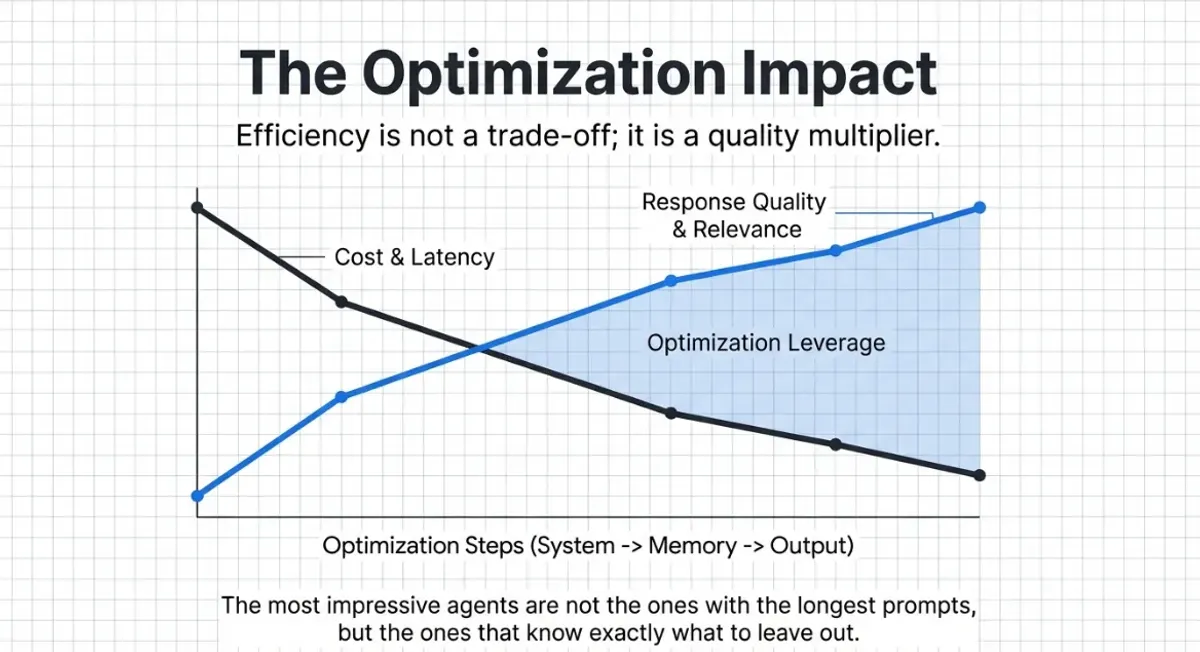
De la investigación a funcionalidades en producción.
Cada optimización que descubrimos se convierte en una funcionalidad que puedes activar. Sin cambios de código.
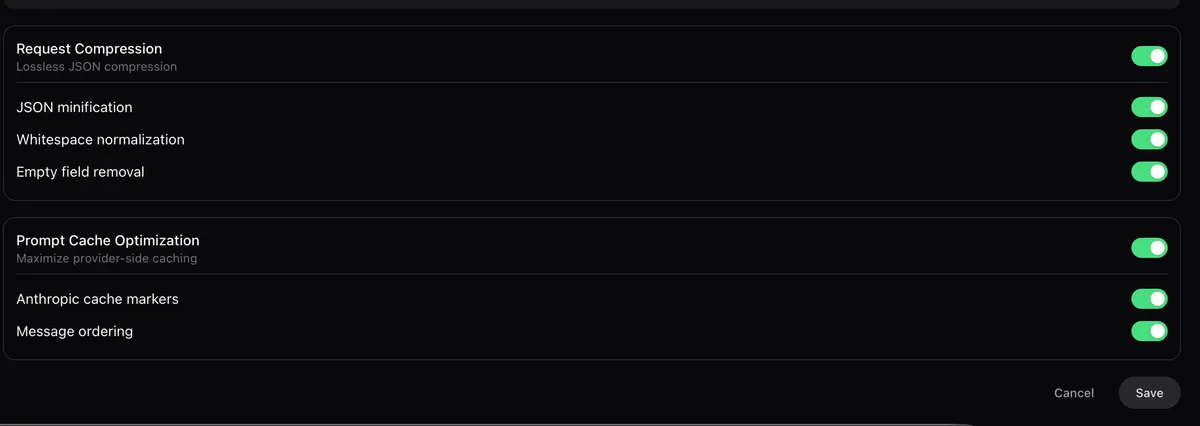
Compresión de Peticiones
Compresión JSON sin pérdida que ahorra tokens en cada llamada API: minificación JSON, normalización de espacios y eliminación de campos vacíos.
Optimización de Caché de Prompts
Maximiza el caché del lado del proveedor para respuestas más rápidas: marcadores de caché de Anthropic y ordenamiento optimizado de mensajes.
Diseña el futuro del rendimiento de agentes de IA.
Únete a nuestro programa de partners de investigación y obtén acceso anticipado a funcionalidades de optimización.
Evaluación gratuita