Reduce tu factura de tokens un 20 a 40%. Sin tocar una línea de código.
El proxy transparente de RenLayer comprime cada petición y maximiza los aciertos de caché de prompts, mientras los topes de presupuesto y la analítica de coste por agente frenan el gasto desbocado antes de que llegue a tu factura.
Solicita una evaluación gratuita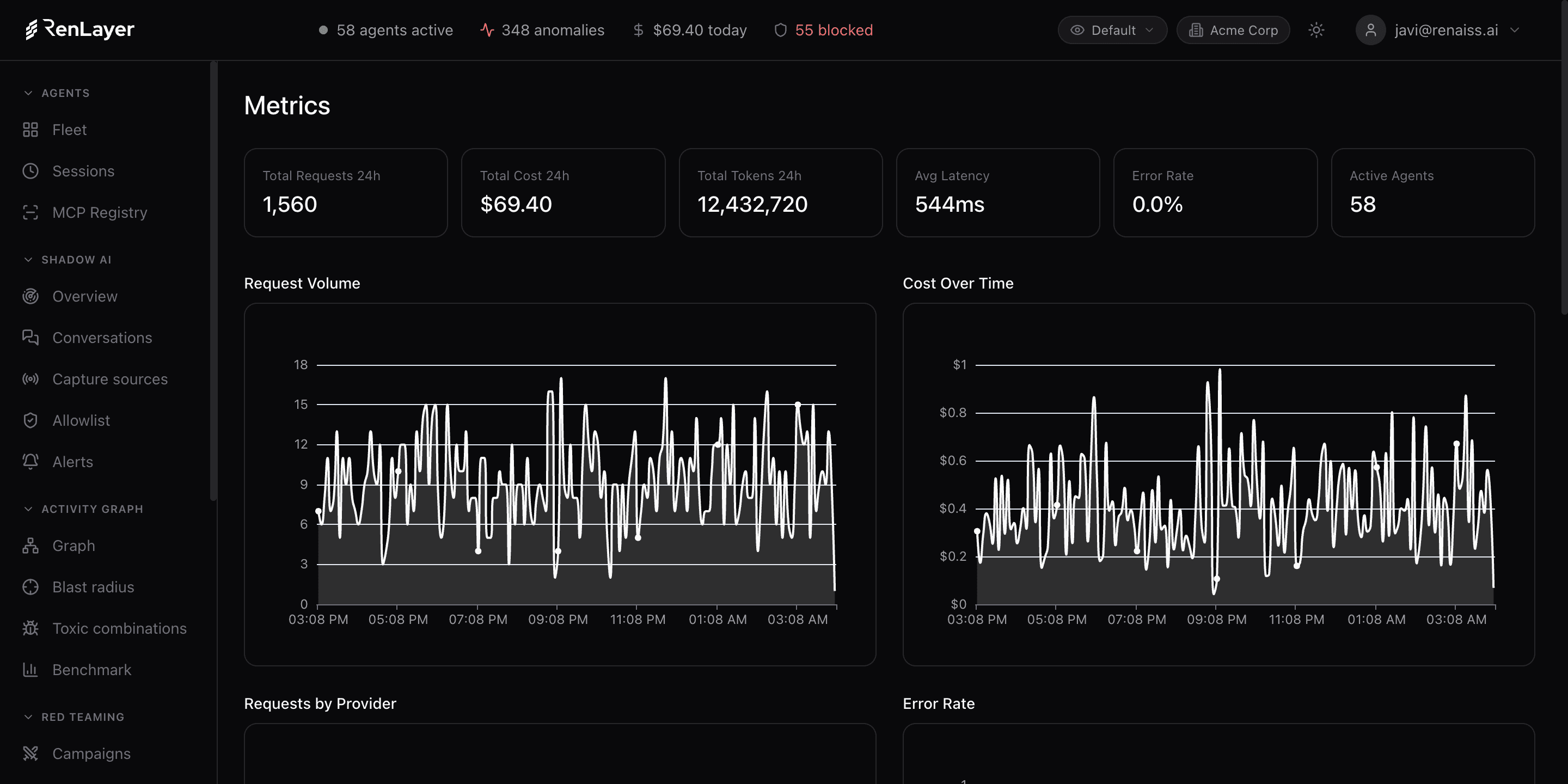
Los agentes de IA fallan en abierto con el coste.
Un solo agente puede multiplicar tu factura sin que te enteres: ventanas de contexto infladas que se reenvían en cada turno, tormentas de reintentos, transcripciones sin truncar, escalado silencioso de modelo y bucles de herramientas sin límite. La mayoría se entera cuando llega la factura. RenLayer hace el gasto visible y controlable desde el día uno.
Lee cómo se dispara el coste de los agentes de IACómo recortamos los tokens
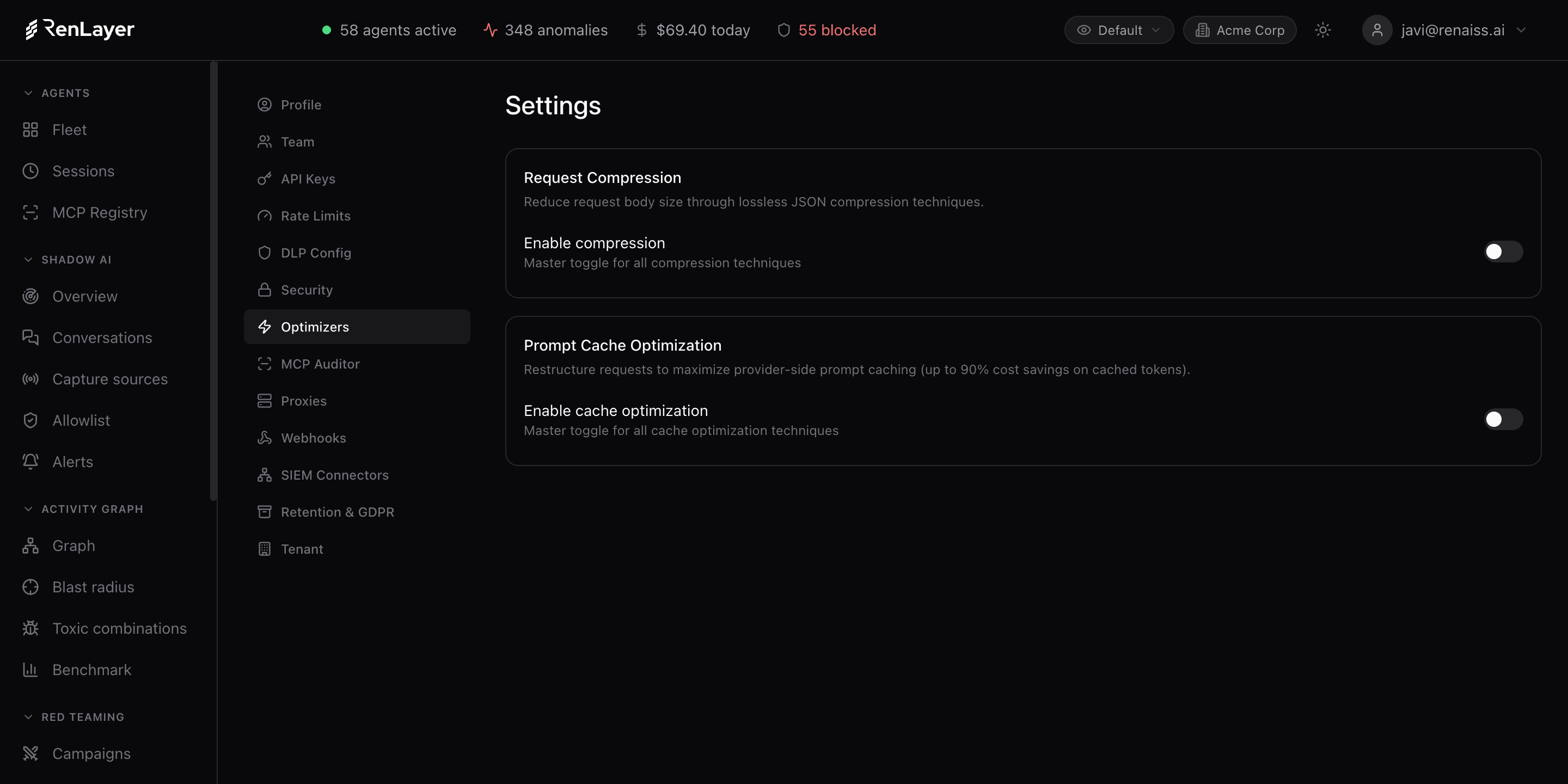
Tres optimizadores corren dentro del proxy y se activan por agente. Sin SDK, sin cambios de código, y se preserva la calidad de la salida.
Request Compression
Compresión JSON sin pérdida en cada petición: minificación, normalización de espacios y eliminación de campos vacíos recortan tokens antes de que la llamada salga de tu red.
Prompt Cache Optimization
Las peticiones se reestructuran para maximizar la caché del proveedor con marcadores de caché de Anthropic y ordenación de mensajes, hasta un 90% de ahorro en tokens cacheados y respuestas más rápidas.
System Instruction Compression
Las instrucciones en lenguaje natural verboso pasan a reglas y restricciones estructuradas, lo que mejora el determinismo y recorta el coste fijo de cada prompt.
La optimización baja la factura. El gobierno la mantiene baja.
El mismo proxy que comprime tokens también aplica los límites y muestra los números que tus equipos de finanzas y plataforma necesitan.
Topes de presupuesto y kill switch
Fija topes por agente y por equipo de peticiones por minuto u hora, tokens por minuto y coste por hora. Para un agente o toda la flota desde un único interruptor.
Políticas de coste
Bloquea cualquier petición cuyo coste estimado supere tu umbral, o restringe modelos caros, con la plantilla de política Cost Guardrail. Sin código.
Analítica de coste y atribución
Datos exactos de tokens y coste por agente, modelo, proveedor, usuario, equipo y departamento, con alertas automáticas ante picos de coste, incluso cuando la UI del proveedor lo oculta.
En producción en menos de un día
1. Apunta tu cliente al proxy
Cambia la URL base al endpoint de RenLayer y añade unas cabeceras. Sin SDK, sin reescritura, sobrecarga de un solo dígito en milisegundos.
2. Activa optimizadores y presupuestos
Activa la compresión de peticiones y la optimización de caché de prompts por agente, y fija topes de presupuesto y políticas de coste desde plantillas.
3. Mira caer el coste
Sigue el coste por agente y modelo en Observe, detecta picos automáticamente y atribuye cada euro al equipo que lo gastó.
FAQ de optimización de coste
¿Cuánto puedo ahorrar de verdad?
La mayoría de equipos recorta del 20 al 40% de los tokens con compresión de peticiones y optimización de caché de prompts, y hasta un 90% en la parte del tráfico que acierta en la caché del proveedor. La cifra exacta depende de tus prompts, modelos y de lo repetitivo que sea tu tráfico, que es justo lo que mide la evaluación gratuita contra tu propio tráfico.
¿La compresión cambia la salida del modelo?
No. La compresión de peticiones es sin pérdida: elimina espacios, minifica JSON y quita campos vacíos sin cambiar la semántica que ve el modelo. La optimización de caché reordena mensajes y añade marcadores de caché; el contenido no cambia.
¿Tengo que cambiar mi código?
No. RenLayer es un proxy transparente. Cambias la URL base y añades unas cabeceras, y luego activas los optimizadores en la consola. Funciona con cualquier cliente y proveedor, y puedes desactivarlo sin romper tus agentes.
¿Cómo se atribuye el coste?
Cada petición se valora con datos exactos de tokens y coste y se une al agente, modelo, proveedor, usuario, equipo y departamento, para que puedas hacer chargebacks y ver exactamente de dónde viene el gasto, incluso cuando la UI del proveedor no lo expone.
¿Puedo limitar el gasto, no solo medirlo?
Sí. Fija topes de presupuesto por agente y equipo en peticiones, tokens y coste por hora, bloquea las peticiones que se pasen con una política de coste y usa el kill switch para parar un agente desbocado al instante.
¿El proxy añade latencia?
Añade una sobrecarga de un solo dígito en milisegundos por petición, y la optimización de caché de prompts suele hacer las respuestas más rápidas al aumentar los aciertos de caché. El enriquecimiento y el logging ocurren después de transmitir la respuesta, así que el cliente nunca espera por ello.
Mira cuánto ahorrarías.
Empieza con una evaluación gratuita. Ejecutamos una prueba en modo sombra contra tu propio tráfico y te enseñamos la reducción de tokens y el gasto que puedes limitar, en menos de una semana.
Solicita una evaluación gratuita