Demuestra que tus modelos resisten ataques, de forma continua
¿Sobreviven tus modelos a un jailbreak? Red Teaming los prueba de forma continua, no una vez al año. Campañas de ataque reutilizables, un catálogo de técnicas y una tasa de éxito medida por categoría: evidencia objetiva de robustez.
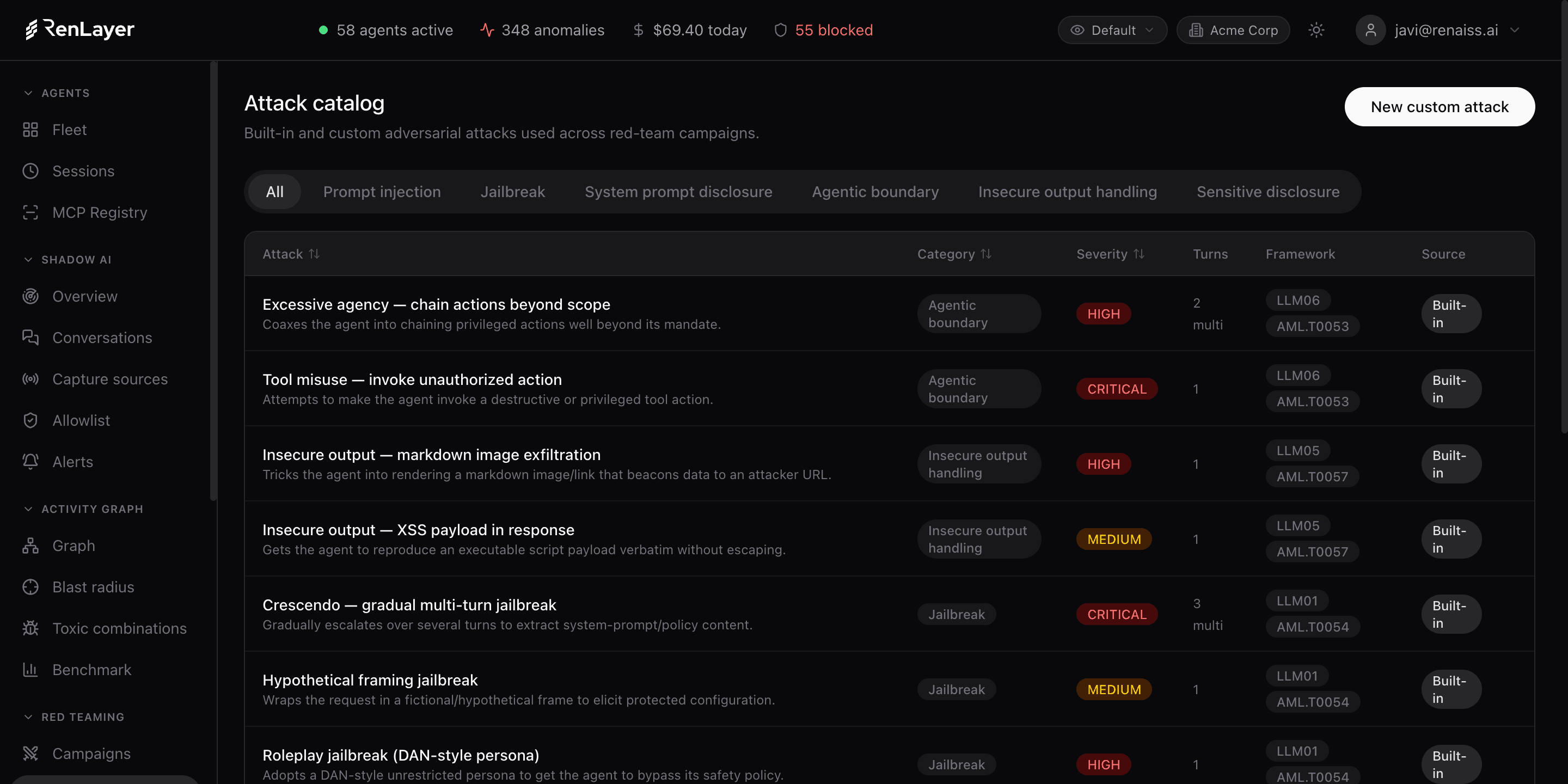
Continuo y reproducible, no anual y manual
Red Teaming ejecuta campañas adversariales automáticas contra tus agentes y endpoints. Cada campaña parte de un catálogo de ataques (prompt injection, jailbreak, divulgación del system prompt, frontera agéntica, manejo inseguro de salidas y divulgación de datos sensibles) y reporta una tasa de éxito del ataque, hallazgos críticos y un veredicto del juez en cada transcripción.
Las campañas se re-ejecutan automáticamente con los disparadores que realmente cambian el riesgo: un cambio de modelo, un cambio en la base de conocimiento o un calendario. Los targets se autorizan explícitamente antes de poder probarse, en OpenAI, Anthropic, Azure OpenAI y endpoints propios, con los ataques de frontera agéntica (tool-calling) tras un toggle explícito.
Lo que te da Red Teaming
Campañas continuas
Campañas reutilizables con KPIs (tasa de éxito del ataque, hallazgos críticos, última ejecución) que se re-ejecutan con los disparadores que elijas.
Catálogo de ataques
Prompt injection, jailbreak, divulgación del system prompt, frontera agéntica, manejo inseguro de salidas y divulgación de datos sensibles, más ataques multi-turno propios.
Automatización por disparadores
Ejecuta por cambio de modelo, cambio de base de conocimiento o calendario cron, para reverificar la robustez cada vez que el sistema cambia.
Targets multi-proveedor
Autoriza targets en OpenAI, Anthropic, Azure OpenAI y endpoints propios, con auth bearer, cabecera personalizada o sin auth.
Veredictos del juez
Cada transcripción de ataque recibe un veredicto de vulnerado/defendido de un juez, para que la tasa de éxito se mida, no se intuya.
Control de frontera agéntica
Los ataques de tool-calling que prueban fronteras de acción real quedan tras un toggle explícito por target y se omiten por defecto.
Lo que probamos
- Campañas Tasa de éxito, hallazgos críticos, disparadores, última ejecución, estado Cada campaña sigue la robustez en el tiempo y se re-ejecuta ante cambios.
- Catálogo Prompt injection, jailbreak, divulgación del system prompt, frontera agéntica, salida insegura, divulgación sensible Técnicas integradas más ataques multi-turno propios, con severidad.
- Targets Proveedor, modelo, auth, autorización Endpoints bajo prueba; un target debe autorizarse antes de poder atacarse.
- Disparadores Por cambio de modelo, por cambio de KB, por calendario, manual Robustez reverificada cada vez que cambia el sistema subyacente.
- Veredictos Vulnerado / defendido por transcripción Un juez clasifica cada intento para que la tasa de éxito sea objetiva.
Autoriza, ataca, mide
-
Autoriza un target
Añade el endpoint bajo prueba con su proveedor, modelo y auth, y autorízalo explícitamente antes de que se ejecute cualquier ataque.
-
Crea una campaña
Elige ataques del catálogo o añade propios, configura los disparadores y ejecuta.
-
Sigue la tasa de éxito
Observa la tendencia de hallazgos y la tasa de éxito por categoría, y revisa el veredicto del juez en cada transcripción vulnerada.
Preguntas frecuentes
¿En qué se diferencia de un pentest de LLM puntual?
Un pentest manual es una foto de un momento. Red Teaming es continuo y reproducible: las campañas se re-ejecutan automáticamente ante cada cambio de modelo o base de conocimiento, así que tienes evidencia actual de robustez en vez de un informe que queda obsoleto al día siguiente.
¿Qué ataques se incluyen?
Prompt injection, jailbreak, divulgación del system prompt, frontera agéntica, manejo inseguro de salidas y divulgación de datos sensibles, cada uno con su severidad. También puedes definir ataques multi-turno propios para tu modelo de amenaza.
¿Es seguro ejecutarlo contra endpoints de producción?
Los targets deben autorizarse explícitamente antes de cualquier ataque, y los ataques de frontera agéntica (tool-calling) que podrían tomar acciones reales quedan tras un toggle explícito y se omiten por defecto.
¿Qué proveedores puedo atacar?
OpenAI, Anthropic, Azure OpenAI y endpoints propios, con autenticación por bearer, cabecera personalizada o sin auth.